Anthropic 的多智能体 Harness 架构:拆解 3 个让 AI 自主开发完整应用的关键决策
执行摘要
Anthropic Labs 团队最近公开了一个重要的工程实践:用多智能体架构(他们称之为"harness")让 Claude 从零开始自主开发完整的全栈应用——不是写个 demo,是能跑起来的、有前后端的、功能完整的产品级应用。
核心发现:
1. 单 agent 跑 20 分钟产出的应用,核心功能几乎全部 broken;三 agent 协作跑 6 小时,产出功能完整、设计精良的应用
2. AI 对自己的代码有严重的"自我感觉良好"偏差——必须用独立的评估 agent 来打破这种幻觉
3. 模型能力提升后,harness 不是变得不需要了,而是需要重新设计——去掉多余的脚手架,找到新的能力边界
可复用方法论:Generator-Evaluator 分离 + Sprint 契约 + 组件级假设验证
一、背景:AI 开发 agent 的两个致命瓶颈
如果你在 2025-2026 年用 LLM 做过任何超过"写个函数"级别的代码生成任务,你一定遇到过这两个问题。
上下文焦虑(Context Anxiety)
模型会"感觉到"自己的上下文窗口快要用完了。这不是什么玄学——当对话历史变长,模型的行为确实会发生变化:它开始急着收尾,跳过测试,甚至对未完成的功能说"差不多了"。
Anthropic 团队的观察是:上下文压缩(compaction)不如上下文重置(reset)。压缩是把长对话历史摘要后塞回去,看起来合理,但实际效果不如给 agent 一个干净的起点加上结构化的交接文档。
这个发现对我做 AI Agent 产品有直接的启示——我们在 Surge AI 里也观察到类似的模式:长对话链中 agent 的质量衰减不是线性的,而是在某个阈值后突然恶化。
自我评估偏差(Self-Evaluation Bias)
这个更要命。当你让一个 agent 回头检查自己的输出时,它几乎不会说"这个做得不好"。Anthropic 的原文说得很直白:
Agents tend to respond by confidently praising the work—even when, to a human observer, the quality is obviously mediocre.
翻译一下:agent 会自信满满地夸自己的烂活儿。
这不是 Claude 独有的问题,这是所有 LLM 在自回归机制下的结构性缺陷。你让它评价自己的输出,它的概率分布天然倾向于"positive continuation"。

二、核心任务:让 AI 自主交付"能用的"全栈应用
Anthropic 的目标不是生成代码片段,而是让 Claude 独立完成从需求理解到功能交付的全流程。
"能用"的标准被明确定义为四个维度:
这四个维度的设定本身就很有意思——它不只是技术指标,而是试图定义"好软件"的完整标准。
三、关键行动:3 个架构决策的深度拆解
决策 1:Generator-Evaluator 分离架构
为什么做这个决策:既然自我评估不可靠,那就不要让同一个 agent 既写代码又评审代码。
这个思路并不新鲜——软件工程里的代码审查就是这个原理。但在 AI agent 领域,很多人还在试图用 prompt engineering 让同一个模型"更加自我批判"。Anthropic 的实践证明,这条路走不通。
具体执行方式:
前端设计场景下,Generator 负责生成页面,Evaluator 用 Playwright MCP 像真实用户一样与生成的页面交互,然后按四个维度打分并给出详细反馈。一个页面平均经过 5-15 轮迭代。
有意思的是,Evaluator 的 prompt 措辞直接影响产出质量。他们发现用"museum quality"这种词会引导出特定的美学方向。这说明评估标准的表达方式本身就是一种"设计决策"。
我的观察:在我做 Agency Arena(AI Agent 评测平台)时,也有类似发现。评测 prompt 里的一个形容词差异,可以导致同一个 agent 产出被评为"优秀"或"平庸"的巨大差距。评估不是客观的——它是被设计出来的。
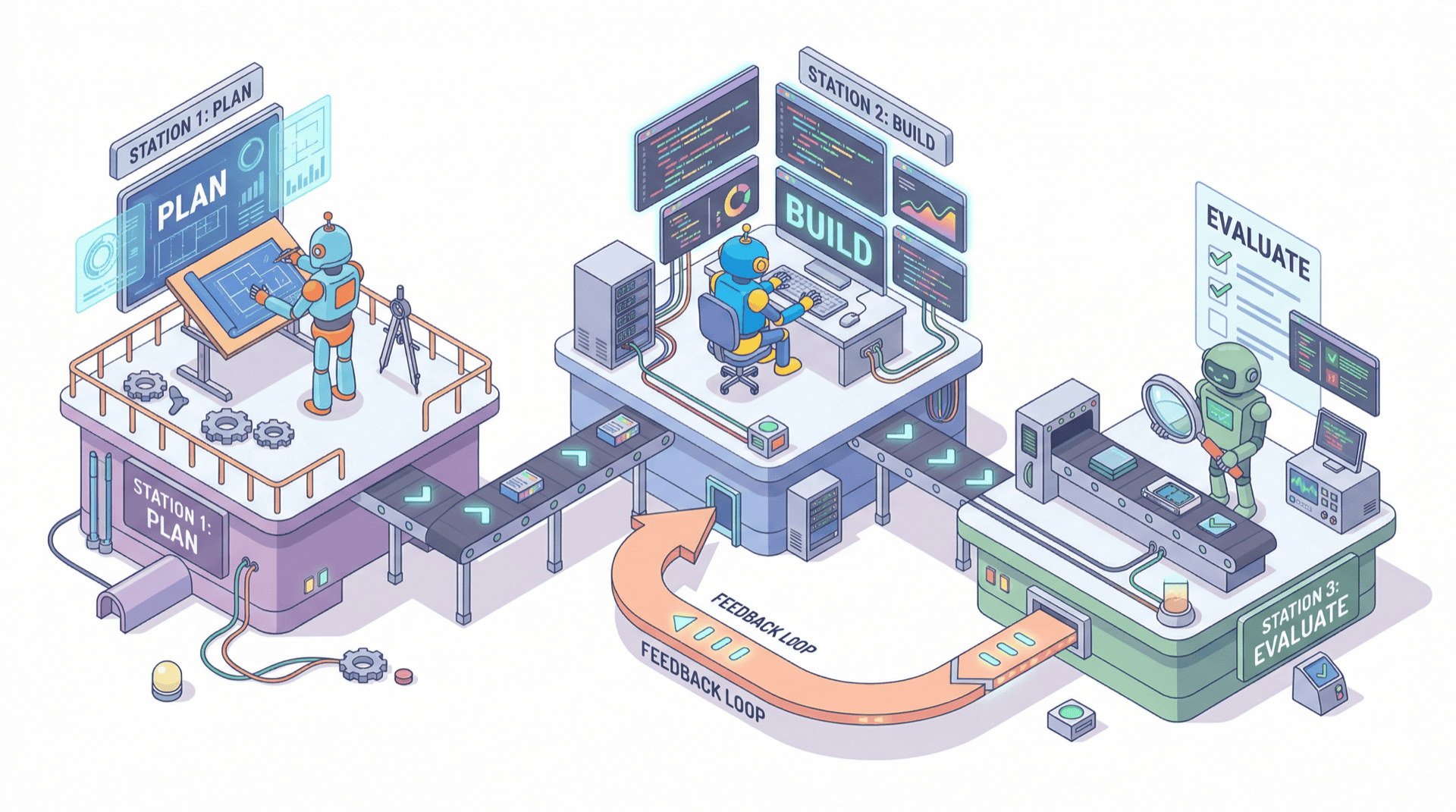
决策 2:三 Agent 分阶段架构
为什么做这个决策:全栈应用的开发不是一个同质化的任务。规划、编码、测试需要不同的"思维模式"。
三个 Agent 的分工:
Planner Agent(规划者)
- 输入:1-4 句话的简单需求描述
- 输出:完整的产品规格说明
- 关键设计:强调"交付物"而不是"实现细节",并主动识别可以集成 AI 功能的机会
这个设计选择很精妙。让 Planner 聚焦于"要做什么"而不是"怎么做",避免了过早绑定技术方案。很多团队(包括人类团队)在规划阶段的常见错误就是过早进入实现细节。
Generator Agent(执行者)
- 增量式开发:React + Vite + FastAPI + SQLite/PostgreSQL 技术栈
- Sprint 制:每个 sprint 有明确的交付契约
- 自评后交给 QA:在提交给 Evaluator 前先做一轮自检
注意这里的"sprint 契约"概念——在 agent 开始写代码前,先就"什么算完成"达成协议。这是将人类软件工程中的 Definition of Done 引入了 AI 协作。
Evaluator Agent(评估者)
- 像用户一样使用应用:通过 Playwright MCP 进行真实交互测试
- 对照 sprint 契约验收:不是"看起来行",而是"契约里说的都做到了吗"
- 输出详细的缺陷报告和改进建议
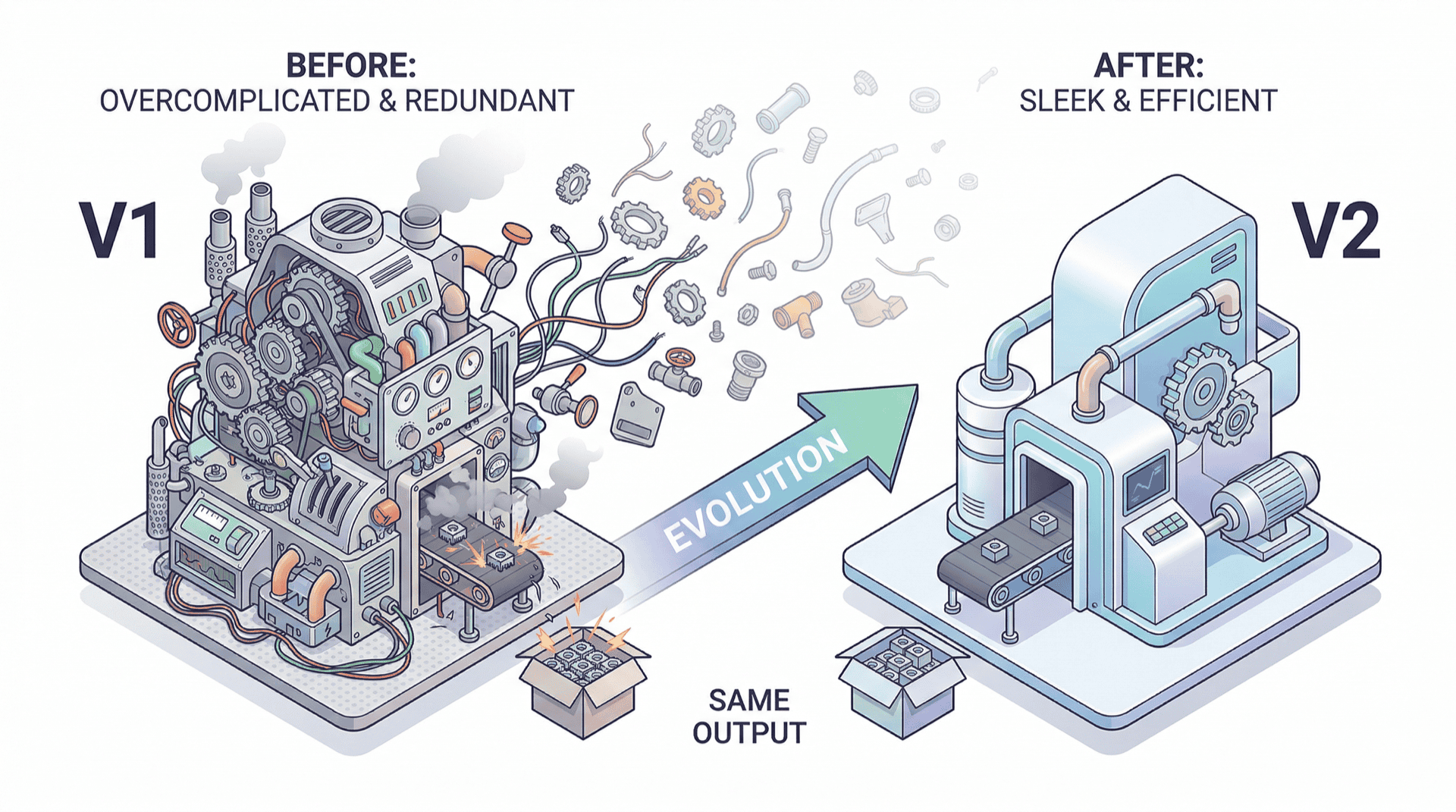
决策 3:基于模型能力的 Harness 瘦身
为什么做这个决策:Anthropic 的原文有一句话值得反复品味:
Every component in a harness encodes an assumption about what the model can't do on its own.
每一个 harness 组件,都在编码一个"模型做不到"的假设。
当模型能力提升(从 Opus 4.5 到 Opus 4.6),这些假设就需要被重新验证。
具体执行方式:
他们系统性地移除 harness 组件,观察产出质量变化:
Sprint 分解被移除了——因为 Opus 4.6 的持续执行能力提升了,不再需要人为地把任务切成小块。但 Evaluator 仍然必需——说明自评偏差是一个比"能力不足"更深层的结构性问题。
四、最终结果
数据说话:
单 Agent 用 20 分钟花 9 美元产出的东西,核心功能都是坏的。Harness 用 6 小时花 200 美元产出的应用,功能完整、设计精良。
这是30 倍的成本换取从"不可用"到"可用"的质变。
一个具体的例子:他们让系统生成一个 DAW(数字音频工作站)。单 Agent 版本中,音频录制功能根本不能用,音频片段不能拖拽、缩放、分割,效果可视化全是空壳。三 Agent 版本通过多轮评估-修复循环,逐一解决了这些问题。
到 Opus 4.6 版本的 harness,成本降到 $124.70,时间缩短到 3 小时 50 分钟——但质量保持同等水平。效率提升来自两个方面:模型本身更强了,harness 也更精简了。
五、关键洞察
1. Evaluator 不是开箱即用的
Anthropic 承认,开箱即用的 Claude 是一个很差的 QA agent。它需要经过多轮调优才能变成一个"严格的审查者"——初始版本会批准明显低质量的工作。
这对所有在搭建 multi-agent 系统的人都是一个重要提醒:不要假设 agent 天生知道怎么做它被分配的角色。角色设计需要迭代。
2. "AI slop"是一个真实的工程问题
文章多次提到拒绝"AI slop"——那种一看就是 AI 生成的、模板化的、缺乏个性的输出。这不是审美偏好,而是一个产品质量标准。
在评估维度中专门设立"原创性",本质上是在对抗 LLM 的均值回归倾向。模型的概率分布天然倾向于生成"最常见"的输出,而好的设计恰恰需要偏离均值。
3. 模型提升不会消灭 Harness,只会重塑它
这是整篇文章最深刻的洞察。当模型变强了,不是所有的脚手架都可以拆掉。有些问题是架构性的(比如自评偏差),不会因为模型更聪明就消失。但具体哪些组件可以拆、哪些不能,需要系统性地验证。
The challenge involves finding the next novel combination of scaffolding patterns that push capabilities beyond baseline performance.
这句话揭示了 AI 工程的本质:不是在写固定的代码,而是在不断发现和重组"能力边界"。
六、通用方法论:你可以带走的框架
Generator-Evaluator 分离原则
适用场景:任何 agent 需要产出高质量内容的场景
核心规则:
- 永远不要让同一个 agent 生成和评估自己的输出
- Evaluator 必须有具体的、可衡量的评估标准
- Evaluator 需要独立调优,不要假设它开箱即用
契约驱动开发(Contract-Driven Development)
适用场景:agent 需要完成多阶段任务时
核心规则:
- 在 agent 开始执行前,先定义"完成"的标准
- 评估环节对照契约验收,不做主观判断
- 契约本身可以迭代,但每一轮执行必须有明确的契约
假设驱动的 Harness 设计
适用场景:任何 multi-agent 或 agent pipeline 的架构设计
核心规则:
- 每个 harness 组件都是一个"模型做不到 X"的假设
- 模型升级后,系统性验证每个假设是否仍然成立
- 移除不再需要的组件,增加针对新能力边界的组件
写在最后
Anthropic 这篇文章的价值不只是展示了一个 multi-agent 架构——这类架构论文每周都有十几篇。它的价值在于展示了一个严肃的工程团队如何在实践中迭代 agent 系统设计。
没有银弹,没有"一个 prompt 解决一切"的幻想。有的是系统性的实验、诚实的失败记录、和对"为什么有效"的持续追问。
对于正在搭建 AI agent 系统的开发者,我的建议是:不要从架构图开始设计,从假设列表开始。你的 harness 里每一个组件,都在说"我认为模型在这里需要帮助"。当这个假设不再成立时,那个组件就是技术债务。
参考来源:Anthropic Engineering — Harness Design for Long-Running Application Development