微调真死了吗?2026 年我把它送进 RAG 的影子里

引子:那个被所有人相信的"真理"
五月 13 号 swyx 在 AINews 扔了个标题:"The End of Finetuning"。
评论区分成两派。一派欢呼"老子早就不微调了,RAG 真香"。另一派 Cursor 的工程师默默贴出他们最新发布的微调代码补全模型。两派都觉得自己赢了。
我读完原文,觉得这是个标题党——但论点比标题诚实。微调没死。死的是 2023 年那个"微调就是把知识压进模型权重"的微调。
2026 年的微调,已经悄悄退到 RAG 和长上下文的影子里。如果你还按两年前的脚本做选型,你会在错误的地方花预算,并且发现"微调出来的效果不如 prompt + RAG",然后开始怀疑微调技术本身。
不是微调不行了。是它的位置变了。
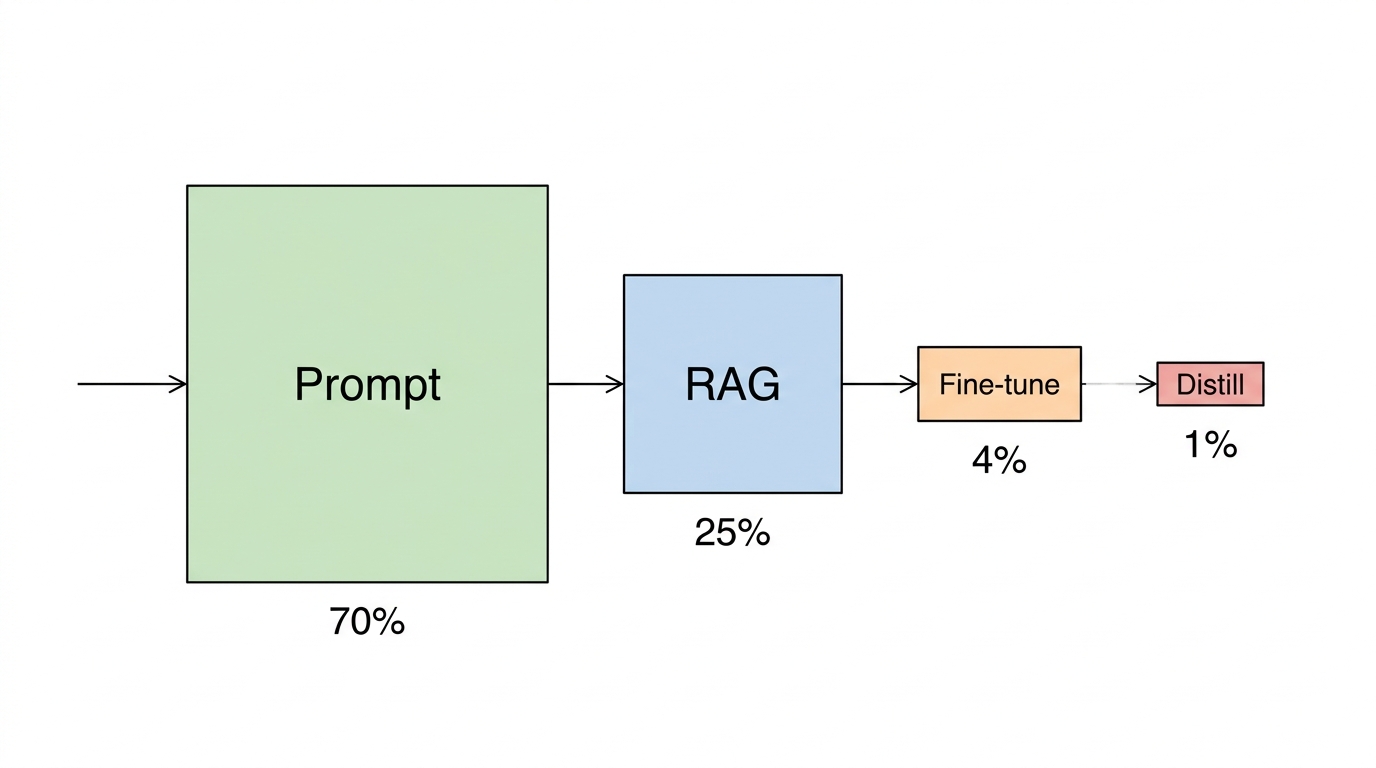
论点
2026 年决策序列:先 prompt,不行上 RAG,不行才微调,最后才蒸馏。
一年前这个序列里"先 prompt"是新东西,现在它能吃掉 70% 的场景。RAG 处理掉再剩下 25% 里的大头。留给微调的,是那个被很多人误解的最后 5%。
这个 5% 不是"重要性 5%",而是"覆盖场景 5%"。微调在它擅长的地方仍然不可替代。问题是大部分团队从来没识别清楚那个地方在哪。
论证 1:成本曲线已经翻转
两年前微调贵、RAG 便宜,这是常识。
2026 年这个常识已经倒过来一次,又再倒过来一次。先看数字:
- LoRA 微调一个 13B 模型,50K 样本,一次跑下来 $400-1200。比 2023 年的全参数微调降了一个数量级。
- 一个生产 RAG 系统,10K queries/day、500K 文档语料,月成本 $4K-9K。其中向量库托管 $1200/月、embedding 刷新 $800/月、LLM 调用 $2500-5500/月。
- 临界点在 200K 调用每月。低于这个量,RAG + frontier API 比微调小模型便宜。高于这个量,微调小模型每次调用能便宜 70-90%。
但成本只是表象。真正的转折是长上下文 + prompt cache。
Gemini 1M token、Claude 200K token、Anthropic prompt cache 70-90% 命中率。以前必须塞进权重的文档,现在塞进上下文也跑得快、跑得准——而且省去了训练的所有麻烦。一段 100K token 的稳定 system context,缓存命中后单次调用边际成本接近零。
这个变化的杀伤力比 LoRA 降价大得多。它把"知识注入"这条微调最大的应用场景,整个搬到了上下文里。
论证 2:底层逻辑
抛开数字,从机制看。
微调的本质是把一组用例的统计规律压缩进模型权重。这个压缩过程不可逆。你要改一个事实,得重新跑训练。
RAG 是查表。事实在向量库里,改库就改事实。
在一个"事实每周都在变"的世界里,把事实压进权重等于在沙滩上盖房子。合规规则每月更新,产品文档每周改,客户名单每天动——这些东西塞进权重,下周就过期。塞进 RAG,下周改一条记录就行。
更隐蔽的成本是可解释性。微调模型给出一个答案,你很难说清"它为什么这么说"。RAG 给出答案,你能精确到"它引用了文档 X 的第 Y 段"。在 B 端、在监管行业、在 AI 必须做错可追溯的场景,这个差别决定生死。
我在保险、银行、汽车金融的 AI 项目里反复看到同一个模式:客户要的不是"模型说什么",而是"模型为什么这么说"。微调没有给后者的答案。
论证 3:那为什么 Cursor 还在微调?
如果论点这么清楚,为什么 Cursor、Cognition 这些头部公司反而增加微调投入?
因为他们微调的不是"事实",是"行为"。
Cursor 微调的是代码补全的行为模式——光标在某种上下文里应该补出什么风格、什么缩进、什么命名习惯。这些东西没法用 RAG 注入。它们是行为,不是知识。
这是关键差别。2026 年还值得微调的,全是行为微调。
- 品牌口吻:每条客服回复都要符合你公司的语气。
- 固定 schema 输出:每次都要吐出严格的 JSON,且字段名必须是这五个。
- 低延迟约束:每次查询不能容忍 RAG 那一跳,要求 100ms 内出结果。
- 高并发省钱:每月 200K+ 次调用,微调小模型把单价压到 frontier API 的 10%。
这四个场景的共同点是:你要的是模型"以某种方式"做事,不是模型"知道"某件事。
把这条边界画清楚,你就不会再在错误的地方花预算。
反方质疑
"可是我们公司微调过,效果就是比 RAG 好。"
可能是真的。但你的"好"是哪个维度的好?
如果你说的是"回答更准确" — 大概率是因为你的 RAG 没做好。retrieval recall 太低、chunk 切得太碎、reranker 没接、prompt 没引导。这些都是 RAG 工程问题,不是 RAG 概念问题。
如果你说的是"回答更稳定一致" — 那是行为问题,恭喜,你的微调用对了。
如果你说的是"延迟更低" — 那也是行为/性能问题,微调用对了。
如果你说的是"模型知道了我们的产品" — 这是知识问题,你应该是在用 RAG。微调"教会"模型一个事实,等下个月那个事实变了,你的模型就是错的,而且改不掉。
"那长上下文塞 500 页文档也行?为什么还要 RAG?"
塞得进去不代表塞得好。模型在 200K 上下文里 retrieve 一个 needle 时,性能掉得很厉害——这是 needle-in-a-haystack 测试反复证实的。RAG 帮你只塞最相关的 5 段,质量比塞 500 页全文高一个台阶。
长上下文是 RAG 的补充,不是替代。当你的知识库小到能整本塞进 prompt cache,跳过 RAG 是合理的。否则别跳。
结论:三个判断

如果你今天要做 LLM 应用的技术选型,2026 年的三条判断:
- 想让模型"知道"某件事——不要微调。 给它放在 RAG 里,或者 system prompt 里如果量小。微调注入知识的边际收益已经被长上下文吃光了。
- 想让模型"以某种方式"做事——微调有用,但先试 prompt。 prompt + few-shot 解决不了的行为问题,再考虑 LoRA。直接跳到全参数微调通常是工程团队的傲慢。
- 想让模型在边界场景"想得更深"——别微调,让它用工具加长上下文。 这是 2025 年下半年起最被低估的路径。tool use + 多步推理 + 长上下文 cache,比微调一个"会推理"的模型便宜十倍且可解释。
我自己产品里——Surge AI、Agency Arena——一年前还有四个微调任务。今年砍到零。全换成 RAG + prompt cache + tool use。
砍下来的预算去哪了?eval。
因为不微调之后,模型行为的可解释性必须靠 eval 撑住。我们现在每个 prompt 改动都要跑一套 200+ 题的回归集。这个钱花得值——它替代了微调本来该提供的"行为稳定性保证",而且改起来比重训快两个数量级。
金句
微调没死,它只是不再用来背书。
把事实塞进权重,就像把电话号码刻在墓碑上——改不了,也丢不掉。
2026 年还在微调的人,要么是顶级工程团队在做行为微调,要么是没分清楚"知道"和"以某种方式"的差别。