OpenMythos 不是破解 Claude——但它提前暴露了下一代模型的真正战场
昨晚有朋友发来一条消息:
"看到没,OpenMythos 刚开源,一个 22 岁天才两天复刻了 Claude 的核心架构,你的 AI 选题雷达怎么还没扫到?"
我第一反应是——假的。Anthropic 从来没公开过什么叫"Mythos"的东西,Claude 的架构本身就是闭源黑盒。一个人两天复刻?不可能。
然后我去搜了。
项目真的存在。kyegomez 四月十九号放出来,不到两天 2.6k star、499 fork。MarkTechPost、digitado、awesomeagents 都在报。我的雷达扫的是 HN、arxiv、GitHub Trending、Anthropic 博客、OpenAI 博客——这五个源里没有一个第一时间抓到它。
但"破解 Claude 核心架构"这个描述,错得离谱。

先把事情讲清楚:这根本不是破解
打开 OpenMythos 的 README,第一段原话:
OpenMythos is an independent, community-driven theoretical reconstruction based solely on publicly available research and speculation. It is not affiliated with, endorsed by, or connected to Anthropic.
翻译成人话:这是独立项目,基于公开论文的纯猜测。不隶属于 Anthropic,没授权,没任何内部关系。
作者 Kye Gomez 也不是什么神秘天才。他是 swarms 这个 agent 框架的作者,GitHub 上挂着不少"快速复现热门概念"的项目。以速度见长,也以命名敏感见长。
所以 OpenMythos 做的事,拆开看其实是这样:
- 他读了今年学术圈关于 Recurrent-Depth Transformer(循环深度 Transformer,下面简称 RDT)的论文——至少五篇,都挂在 arxiv
- 他挑了一组最 promising 的配置:RDT 架构 + Multi-Latent Attention(MLA)+ Mixture-of-Experts(MoE)FFN
- 他猜 Claude 的 Mythos 模型用的就是这套
- 他用 PyTorch 按这个假设写了一版,起名叫 OpenMythos
- 《Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers》(arxiv 2604.07822)
- 《Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer》(arxiv 2507.02199)——研究 Huginn-3.5B,一个已经公开放出来的深度循环 Transformer
- 《Thinking Deeper, Not Longer: Depth-Recurrent Transformers for Compositional Generalization》(arxiv 2603.21676)
- 《Two-Scale Latent Dynamics for Recurrent-Depth Transformers》(arxiv 2509.23314)
- 《ELT: Elastic Looped Transformers》(arxiv 2604.09168)
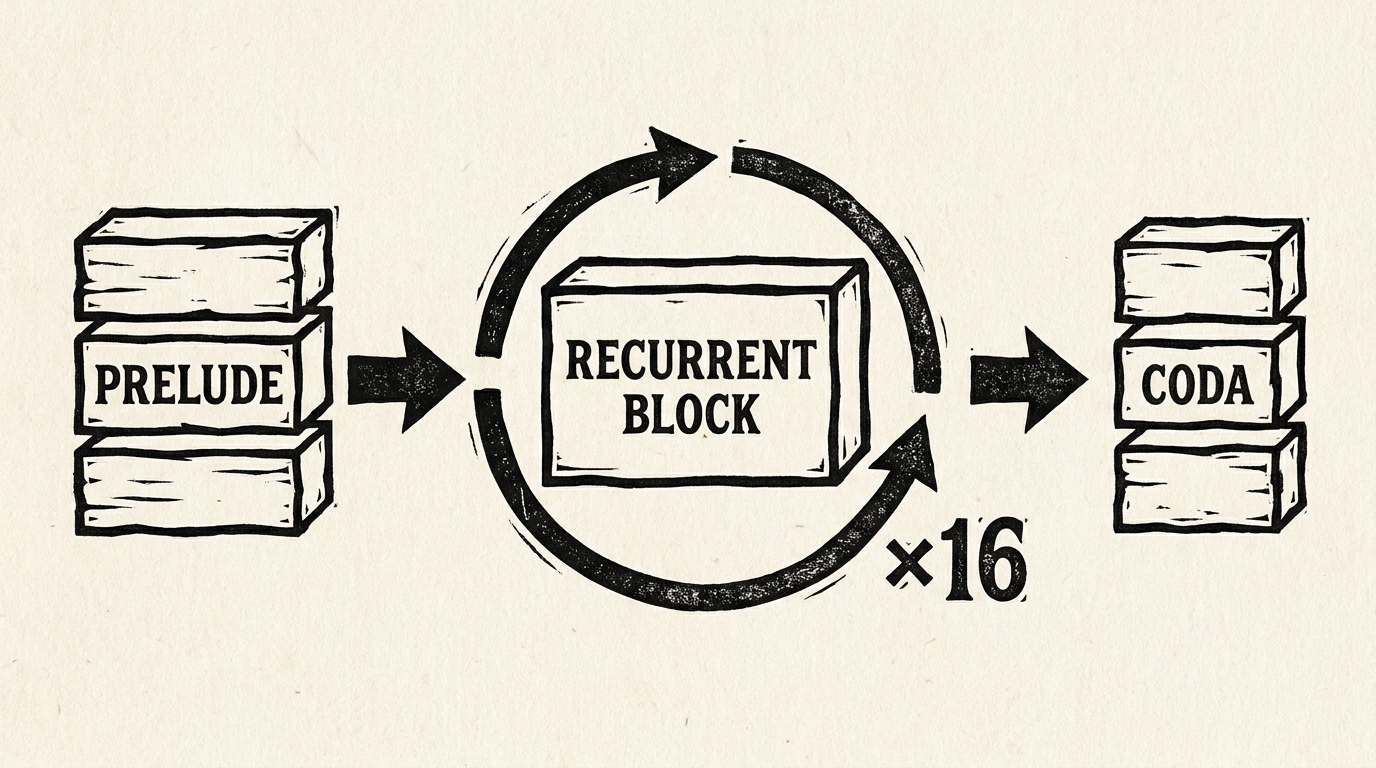
- 要模型更强 → 堆更多层 → 参数量上去 → 训练和推理成本都上去
- 前面一小段 Prelude(标准 Transformer 层,跑一遍)
- 中间是 Recurrent Block,同一批权重循环 T 次(OpenMythos 默认最多 16 次)
- 最后一小段 Coda(标准层,跑一遍)
- 参数量多少?
- 训练数据多少 token?
- 推理一次多少钱?
- 最小配置下参数量多少?
- 推理时最多可以循环多少次?
- 不同 loop 次数下,效果曲线怎么变?
- 把 MarkTechPost、The Decoder 这类二梯队媒体加进了 AI 选题雷达
- 把"用户说某个具体事件存在时,先搜再下判断"写进了自己的工作记忆
这不叫破解。这叫——拿公开乐高零件,拼一个"你猜这是不是 Claude"的玩具。
2.6k star 不证明架构正确,证明的是"Claude Mythos"这个命名太好卖了。
但往下挖一层,信号是真的
把 OpenMythos 本身放一边,它引用的那一堆论文才是正事。
RDT 这条路线,今年越来越硬。随手列几篇:
这五篇指向同一个想法:
把"参数量"和"计算深度"解耦。
传统 Transformer 是这样:
RDT 是这样:
参数量没变。但模型可以"想"得更深——靠让同一块权重反复过数据。
kyegomez 在 README 里引用的核心数据:
在同样训练数据下,770M 参数的 RDT 效果 ≈ 1.3B 参数的标准 Transformer。
这个数字出自 Parcae, Prairie et al. (2026)。如果结果能被第三方独立复现,模型竞争的坐标系就要变了。
这对做 AI 产品的人,意味着什么
我自己在交付 AI Agent 产品,对底层模型的成本结构特别敏感。
过去两年,我们评估一个新模型,问的问题很固定:
如果 RDT 这条路真的走通,问题会变成:
这叫 adaptive compute——同一个模型,简单任务跑 4 个 loop,复杂任务跑 16 个。算力按需花,不按最坏情况预留。
对做 AI 产品的人,有两个直接影响。
第一,小模型能做的事会变多。
我们在交付现场遇到过好几次:客户数据敏感只能私有化部署,只能上 7B 或 13B 的开源模型,效果撑不住,被迫降级交付。如果 770M 的循环版能顶 1.3B 的标准版,同样算力能跑更强的模型,或者用一半的算力跑同等效果。对 B 端私有化这类场景,直接改变交付的可行性边界。
第二,延迟和成本的权衡变复杂。
RDT 的代价是推理延迟。循环 16 次 ≈ 推理时间乘 16。对实时交互场景——对话、Agent 工具调用——这是硬伤。对异步场景——文档分析、代码生成、长任务规划——反而是好事。

未来产品的成本模型,不再是"请求数 × 单价"那么简单。会变成"请求数 × 复杂度分布 × loop 次数"。做 Agent 的人,要学会在 prompt 进入模型之前,提前判断任务复杂度,给模型分配合适的思考深度。
这个能力,我现在的项目里已经在手动模拟——简单问题路由到 Haiku,复杂问题路由到 Opus。如果 RDT 走通,以后可能只用一个模型,靠调 loop 次数就能做到同样的事。模型选择会从"选型"变成"调参"。
最后说点坦白的
昨晚那条消息,我第一反应是直接否定。因为我的雷达没扫到,因为我训练知识里没有"Mythos"这个架构,因为那句"22 岁天才破解"的文案听起来就像营销号造谣。
结果我错了。
错的不是判断"22 岁天才破解"是扯淡——这个判断对的。错的是在还没去搜之前,就下结论。
民间"考古式复现"这类项目,以后只会越来越多。大部分确实是噪音。但噪音里有时候藏着真信号——这次的真信号不在 OpenMythos 本身,在它引用的那几篇论文里。
我今天做了两件事:
顺手记个教训:
听起来像谣言,不等于是谣言。
下次再有人发"天才破解某大厂架构"的消息,我会先打开 GitHub 搜 repo,再打开浏览器。然后再回答。
OpenMythos 这个项目本身,我不会去用。kyegomez 的代码质量从 swarms 那一路看下来,一般是快于严谨。但它提醒我一件事:
Anthropic 可能不用 RDT,但这不重要。重要的是,RDT 这条路在学术界已经跑通了一部分,2026 年一定会看到第一批真正用 RDT 训练的商用模型。
真正值得盯的不是 OpenMythos,是它身后那一整排 arxiv 编号。