你的 Agent 记忆,不属于你
如果我问你:构建一个 AI Agent,最重要的技术决策是什么?
大部分开发者的回答是:选模型、选框架、设计工具链。记忆?那是后期的事。等 Agent 跑起来了,接个向量数据库,挂个 RAG,记忆就有了。
这是 2026 年 AI 开发者圈子里最危险的认知陷阱。
4 月 8 日,Anthropic 发布了 Claude Managed Agents。这不是又一个 Agent 框架——它把 Agent Harness(智能体协调层)和长期记忆完全封装进了 API 内部。不开放源码,不透明存储逻辑,不支持记忆迁移。
三天后,LangChain 创始人 Harrison Chase 发文警告:「如果你使用闭源 Harness——特别是藏在私有 API 后面的那种——你就是在选择把 Agent 的记忆主权交给第三方。」
同期,Letta(原 MemGPT)联合创始人 Sarah Wooders 在推特上说了一句话,直接戳破了行业的集体幻觉:
「记忆不是插件,它就是 Harness 本身。」
这篇文章,我要把这句话彻底拆开给你看。

先搞清楚一件事:什么是 Agent Harness
Agent Harness 这个概念,在中文圈很少被准确理解。
简单说,Harness 是大模型、工具和数据之间的核心协调层。你可以把它理解为 Agent 的操作系统。它负责的事情包括:上下文管理、工具调用、状态处理、流程编排,以及——记忆管控。
Agent 开发走到今天,经历了三个阶段。初代只靠 RAG 链,把文档向量化喂给模型,没有复杂流程。中期模型能力提升,诞生了 LangGraph 这类编排工具。到了现阶段,模型已经足够强,Agent Harness 成为核心基础设施。
关键在于,Harness 不会被模型吸收。
行业有一种流行误解:模型越来越强,Harness 会被整合消失。
事实恰恰相反。
3 月 31 日,Claude Code 因一个 `.npmignore` 配置错误,意外泄露了完整源码。51.2 万行 TypeScript,横跨约 1,900 个文件。全部是 Harness 代码。其中藏着一个叫 KAIROS 的后台守护进程——在用户空闲时自动执行记忆整合(内部称为 "autoDream")。三层记忆架构:MEMORY.md 作为轻量索引,话题文件按需加载,长期记忆独立存储。
这是 Anthropic 自己的团队——全球最强的大模型团队之一——在模型能力已经极强的情况下,仍然重度投入 Harness 建设的铁证。
旧的脚手架会被新方案替代,但 Harness 绝不会被模型吞噬。
所以,Harness 选型是一个长期决策,直接决定你的记忆主权归属。
核心认知颠覆:记忆不是插件
这是本文最重要的观点,也是行业最普遍的认知误区。
绝大多数开发者把记忆当作可插拔的独立模块——先把 Agent 跑起来,后期接个 RAG,存个向量库,记忆就搞定了。
错了。
记忆的核心决策——上下文什么时候压缩、历史怎么存储和查询、Agent 是否有权限修改自己的 System Prompt——这些全部发生在 Harness 内部。外部插件根本无法介入。
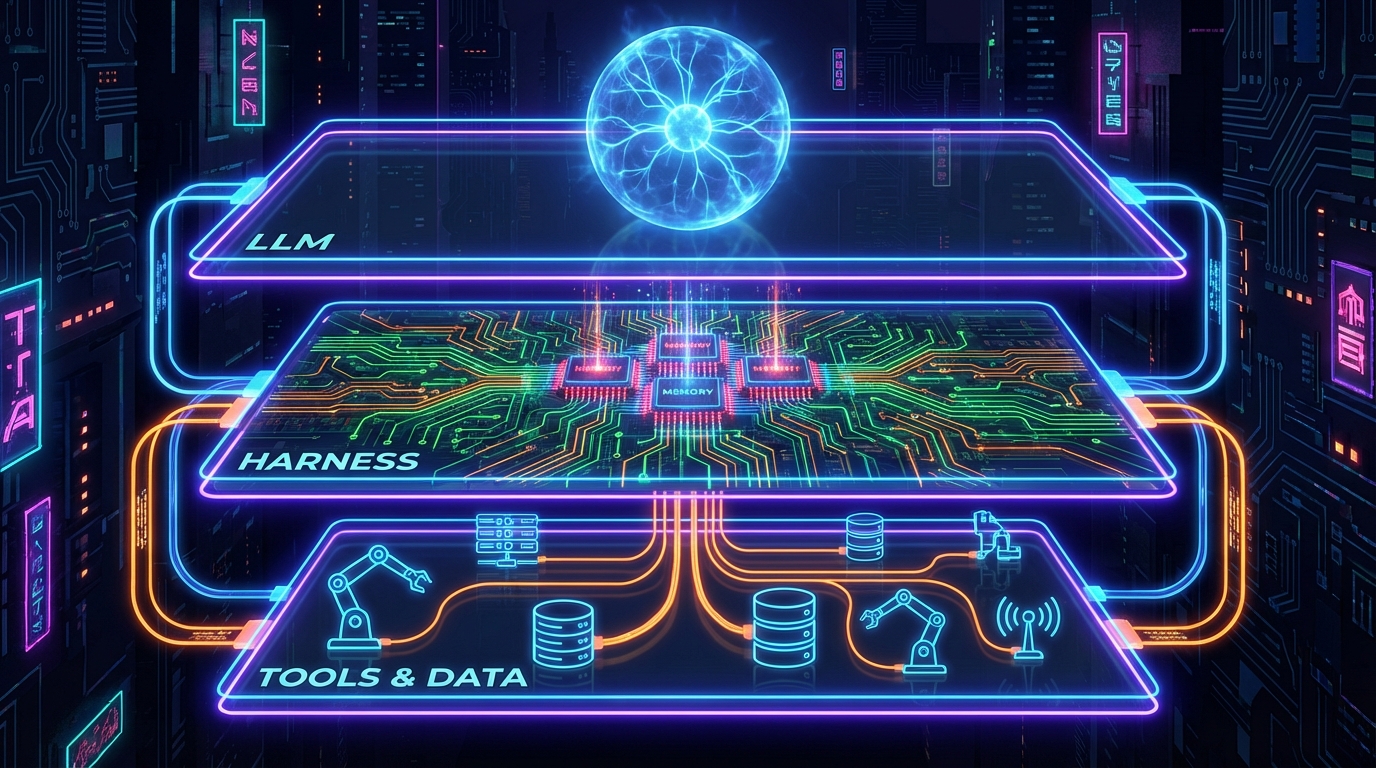
Sarah Wooders 的 MemGPT 是最好的佐证。很多人以为 MemGPT 是一个"记忆插件",可以接到任何框架上。但如果你读过源码,会发现 MemGPT 本身就是一个有状态的 Engine Harness。它的三层记忆体系——Core Memory(类似 RAM,在上下文中)、Recall Memory(可搜索的对话历史,类似磁盘缓存)、Archival Memory(长期冷存储,通过工具调用访问)——全部直接内建在 Harness 中。
记忆是 Harness 工具能力的自然产物,不是外挂的附件。
用一个类比:记忆和 Harness 的关系,就像驾驶和汽车。驾驶不是汽车的配件,它是汽车运行的核心。你不可能买一辆车,然后说"驾驶功能后期再接"。
当你选择了一个 Harness,你就已经做出了记忆主权的决策。只是大多数人在那个时刻并不知道。
商业逻辑:为什么厂商要锁死你的记忆
理解了记忆与 Harness 不可分割,下一个问题是:为什么大模型厂商要把记忆锁死在自己平台上?
答案残酷但简单:因为模型 API 锁不住你,只有记忆能锁住你。
2026 年的现实是,大模型 API 高度同质化。GPT-4o、Claude Opus、Gemini Ultra,在大多数任务上的差异不足以构成迁移障碍。一个无状态的 API 调用,今天用 Claude,明天换 GPT,只需要改一行 endpoint。切换成本几乎为零。
这对厂商来说是噩梦。
但记忆改变了一切。
一个有记忆的 Agent,每多使用一天,就多积累一天的个性化数据:用户偏好、语气习惯、工作流程、交互历史。这些数据像复利一样滚动增长,形成一个专属的、不可替代的数据集。使用越久,Agent 越智能,迁移成本越高。
Harrison Chase 在博文中举了一个真实案例:某团队的内部邮件助手,积累了数月的个性化记忆后被意外删除。团队从模板重新创建了一个——功能完全一样,但体验大幅下降。所有偏好规则、语气调整、流程习惯,全部需要从零调教。
这就是记忆的价值。也是厂商锁定你的真正筹码。
当你的记忆存在平台的服务器上,迁移意味着从零开始。你被迫留下,不是因为模型更好,而是因为你的记忆在这里。
封闭 Harness 的三级风险
不是所有的锁定程度都一样。风险可以划分为三个等级,由轻到重,且每一级都不可逆。
一级风险:轻度锁定——有状态 API
代表:OpenAI Responses API、Anthropic 服务端压缩。
对话状态存在平台服务器上,格式私有。换模型后,你的历史对话线程无法迁移。这是最轻的一级,但已经开始建立迁移成本。
二级风险:中度锁定——闭源 Harness
代表:Claude Agent SDK(底层 Claude Code 不开源)。
记忆的存储方式、格式、逻辑全为黑盒。你看不到、改不了,换框架后也读不了记忆文件。
这里有一个容易被忽略的细节:OpenAI Codex 虽然框架开源,但生成的记忆压缩摘要是加密绑定生态的。脱离 OpenAI,那些摘要就是一堆无法解读的字节。开源框架 + 闭源记忆,本质上仍然是二级锁定。
三级风险:重度锁定——全栈 API 封闭
代表:Anthropic Claude Managed Agents。
这是最危险的形态。开发者对记忆零可见性、零所有权。平台完全掌控 Harness 与记忆。你不知道记忆怎么存的,不知道什么时候被压缩了,不知道有没有被用于模型训练。你唯一能做的,是继续付费使用。
从一级到三级,锁定逐级加深。每一级,都在用你的时间和数据,加固平台的护城河。
利益相关,不等于观点错误
说到这里,必须说一句公道话。
Harrison Chase 主推 LangChain,Sarah Wooders 主推 Letta。两个人都是开源 Harness 产品的核心推动者。他们呼吁"记忆主权",当然有推广自家产品的商业动机。
但利益相关不等于论点错误。
51.2 万行 Harness 源码是客观事实。记忆锁定的商业逻辑是客观事实。封闭 API 的三级风险模型是可验证的客观事实。
就像一个卖防盗锁的人告诉你"你家门没锁"——他确实想卖你锁,但你家门确实没锁。
评估一个论点,看证据链,不看发言人的利益立场。
记忆主权选型三问
讲了这么多,落到实操。如果你今天要选一个 Agent 框架,三个问题必须问清楚:
1. 我的记忆存储在自己的服务器,还是平台的服务器?
如果在平台服务器——你没有主权。不管文档怎么写,Terms of Service 的第 37 条可以随时改。
2. 记忆格式是否开放?换框架后能不能正常读取?
私有格式 = 隐性锁定。即使你能导出,导出的可能是一堆只有原平台才能解析的二进制。
3. 跨平台迁移时,记忆能不能完整带走?
如果不能——那你积累的所有个性化数据,都是平台的资产,不是你的。
三个问题,任何一个答案是"不",你就正在让渡记忆主权。
结论
封闭 API + 记忆锁定,不是 Anthropic 一家的问题。这是整个大模型行业的共同趋势。OpenAI 在做,Google 在做,每一家都在做。
Agent 框架选型,不只是一个工程架构决策。它是记忆主权归属的长期选择。
我不是说开源一定对、闭源一定错。作为一个自己也在用 Claude Code 写代码的实践者,我清楚闭源产品在体验上的优势。
但我要说的是:选择闭源,就是选择让渡记忆控制权。这不是技术选择,是商业选择。
你需要清楚你在选择什么。
记忆是 Agent 最有价值的资产。它不像代码,可以重写;不像模型,可以替换。记忆是时间的沉淀,是不可复制的复利。
谁控制了记忆,谁就控制了 Agent。
你确定要把这个控制权,交给别人?